datasetのTwitterイラスト検索結果。 239 件中 2ページ目


"At least 520 ant species have been transported outside of their native ranges" by humans.
The study reports a dataset of over 146,000 occurrence records to comprehensively map the human-mediated spread of alien #ants.
#Science
#biology
#ecology
⏯️https://t.co/8yu2mpowhm


@UUYProのイラストで学習
Dataset:512×512 52枚(左右反転含む)
step:25000 epooch:390 最終時損失:0.07付近
レイヤ構造:1,2,1 活性化関数:relu 学習率:0.0001 sampling:random
(他Automatic1111の初期設定)
#AIart #AIイラスト #anythingv3
#ファインチューニング #HyperNetwork


@noop_noob test5 has slightly more training images than 1.3.0, and the output is close to 1.3.0, but degraded.
In 1.3.0, I did a 512x512 cropping step, but in test5 I did not do that, but used aspect ratio bucketing.
Maybe the same procedure with the exact same dataset would reproduce 1.3.0



@noop_noob Yes...
I am currently testing a WD1.4 based model that dataset with different contents to verify why v1.3.0's outputs are so nicely.
Even if I increase the number of training images, I cannot exceed the miraculously created 1.3.0. I cannot reproduce it... 😭


After weeks of trial and error to finetune my style using various techniques, datasets, and prompts, trying dozens of datasets / prompts, hundreds of settings and generated thousands of samples, I'm pleased with the results!
#stablediffusion


Happy New Year one and all...and we are off to a roaring start for 2023. Globally, at +0.7°C above the 1979-2000 baseline, this is the highest anomaly I have witnessed for this dataset. @MichaelEMann @KHayhoe @ClimateOfGavin @DrJeffMasters @ProfStrachan @BrianMcHugh2011 @ZLabe


We're surprised by how well it performs, and interestingly - the order in which the training data was organised had a significant impact on the final model.
Another training run on the same dataset in a different order didn't garner anywhere near the same consistency of results.



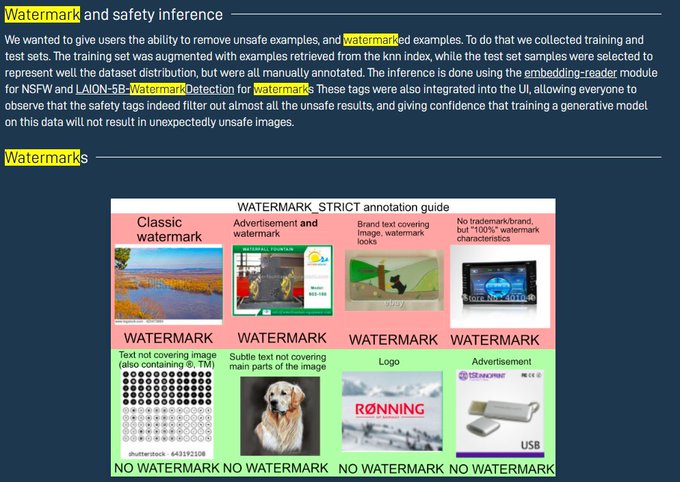
I learned something interesting about A.I. art. The datasets used in Midjourney and Stable Diffusion were created by LAION, a non-profit ai research organization. (1/7)


Let's try a prompt that's nowhere close to the dataset, how about "a zombie". 🧟♂️
This is interesting - the lower strength training (left) gives you a different feel with the pixel art and can deviate further stylistically, while the stronger runs (right) look more polished.


This is one of the strongest datasets in the NFT bear. The memes reign supreme. https://t.co/vix5GgphZp


Very soon AI art generators won't be inspired by any art (already less than 2% of the dataset) + it will still generate art with ease + the whole "stolen remixer" narrative will collapse.
Also AI will have no "tells" like crummy hands + it'll be perfectly coherent.
Then what?


From my datasets
Flowers will grow
And this is AGI
And this is singularity





@somewhere_art @foundation A few from my latest collection. Trained from a dataset including my handmade wool felt artworks, paintings and nature photography.




@thatanimeweirdo @ifandbut01 @SarahCAndersen @Kickstarter I was pretty shocked that when I put in the name of one of my favourite singers for a music video MidJourney actually generated some accurate pictures of her. I thought this would for sure be blocked or like, not be allowed to include her face in the dataset


GM!
Still working on captioning this dataset. Hope your day is pleasant and productive!
#NFTart #AIart #omen #AIIA #psychedelicart


Yes, Twitter, I too agree that the inclusion of art in an AI dataset and claiming it doesn't exist because its 'data' Is pretty fucking ridiculous and deserves a warning, but not like this.




@somewhere_art @foundation Some recent artworks trained from my wool textile artworks datasets.


@cadmiumcoffee It would be a shame if this effect were accelerated by the deliberate feeding of image/text errors into these datasets. Potato hands landscape concept ArtStation realistic big boob.





本日はキャラクターアニメーションと画像生成系の採択論文セッションをしっかり聴講して、関連論文やリポジトリも掘っていたのですが、収穫だったのはこちら
”The DanbooRegion 2020 Dataset”
https://t.co/KFyFYb4fpr
アノテーション領域が与えられたDanbooru、といって伝わるだろうか。12人で評価。


