
高坂さんのイラストまとめ
@t_takasakaFollow @t_takasakaさんをフォローする
フォロー数:439 フォロワー数:21239


スケッチ1枚からイラストやアニメーション、3Dモデルをリアルタイムに自動生成する実験をしています。
UIのスライダーでパーツの形状や色、質感を変更でき、ランダムな選択も可能です。
クリエイターさんから絵を描いたことがない方まで、創作活動を行う方々をアシストするシステムを目指しています。

2Dイラストから3Dモデルを自動生成する実験の続きです。
目パチや口パクをパラメータで指定できるようにしました。今回追加した形状の合成処理は表情以外にも色々応用できそうです。
次は髪の生成を考えてますが、その前に頭部全体のランドマークを追加したデータセットを作る必要がありそうですね。

2Dイラストから3Dモデルを自動生成する実験の続きです。
目のランドマークを増やし、素体の変更を試してみました。今回は @YAN3dcg さんの「ゴトウ(の顔)」をお借りしています。
https://t.co/Ys8pE3qxRP
アニメ調の素体を使うとだいぶ精度が上がりますね。
次は表情の変更を試してみる予定です。


StyleGAN2を使った自動生成の続きで、今回はDanbooru2018データセットを試してみました。以下から顔部分の切り抜き済みデータをお借りしています。
https://t.co/VmfudvpqGK
学習時間は前回と同じくローカルGPUで20時間程度。溶けている部分や過学習っぽいキャラもいるのでまだ調整は必要そうですね。




精度の高い自動着色を使えば線画(原画)から姿勢推定まではできそうです。もしくはcocoのデータセットの画像を線画化して訓練してみるとか、着色済みイラストを姿勢推定した結果から作ったアノテーションと、線画化したイラストの組で訓練してもいいかも知れません(ちゃんと学習できるかは不明です)




「線画(原画)から姿勢推定はできるか」「できない場合、自動着色したらできるようになるか」というのを試したところ「線画からは姿勢推定できない」「OpenCVのdnnモジュールにある自動着色は入力にグレースケールを想定しているため線画は着色できない」という結果に終わった際の成果物となります。


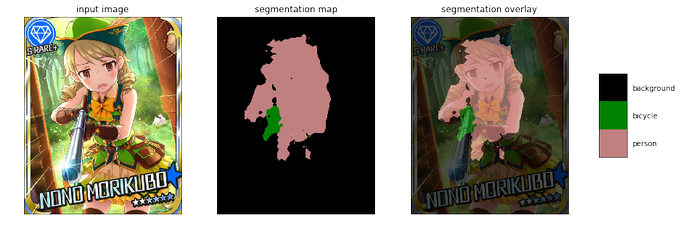

DeepLab V3を試してみました。実写の画像を読ませた場合はデモのように高い精度が出ますが、萌えキャラのイラストだとちょっと相性はよくないみたいです。Mask R-CNNみたいに意外とうまいことやってくれるかなとも期待してたんですが、現状だと難しそうな印象でした。




tf-openposeをPythonからC++に書き換えてTensorFlowのC++ APIから叩く、というやつを試してみてます。ひとまずヒートマップ周りだけ組み込んだ段階だと添付画像のような感じです。とりあえずは動いてるっぽい。

ウェブカメラで撮った映像の顔部分にLive2Dを載せるARサンプルを作りました。ブラウザ上で動きます。
https://t.co/rsFY79KeKU
トラッキングの性能がイマイチなので別のライブラリも調べてみたいですね。眼鏡は認識できないので試すときは外してください。これでぼくもバーチャルYouTuberになれる…!