embeddingsのTwitterイラスト検索結果。 51 件中 3ページ目


The basic idea here is to train MLPs to predict a CLIP image embedding from a text embedding, and vice versa; then normalize and add in the embeddings.




Averaging CLIP embeddings over many permutations of the form "a photograph of X", "X trending on artstation", "X rendered in Blender/Unity," etc produces fairly dramatic improvements in some cases.
e.g. "Jabba the Hutt smoking a cigar"
Left: single text, Right: avg many texts




📌Mastering word embeddings in 10 min with #TensorFlow
👉🏽https://t.co/EpMwT7wfoG
v/ @BigDataQueen_me
#Python #DeepLearning #DL #AI #MachineLearning #ML #100DaysOfCode #DEVCommunity #IoT #IoTPL #IIoT #womenintech #womeininStem #CodeNewbie #DataScience #BigData #NeuralNetwork #NLP https://t.co/ymK6KpGE9s



📌Mastering word embeddings in 10min🕙with #TensorFlow
👇🏽
https://t.co/EpMwT7wfoG
v @BigDataQueen_me
#Python #DeepLearning #DL #AI #MachineLearning #ML #100DaysOfCode #DEVCommunity #IoT #IoTPL #IIoT #womenintech #womeininStem #CodeNewbie #DataScience #BigData #NeuralNetwork #NLP https://t.co/ymK6KpGE9s

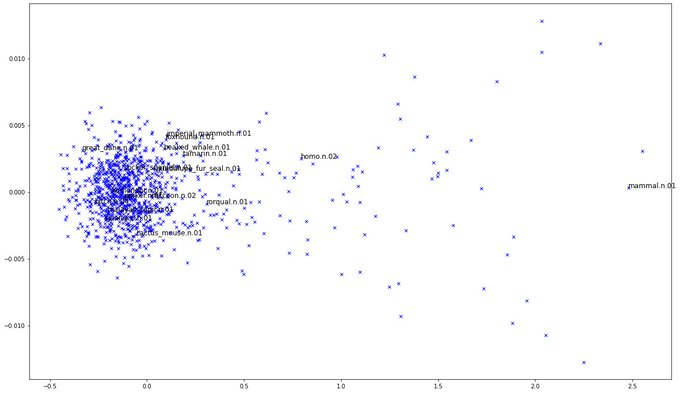
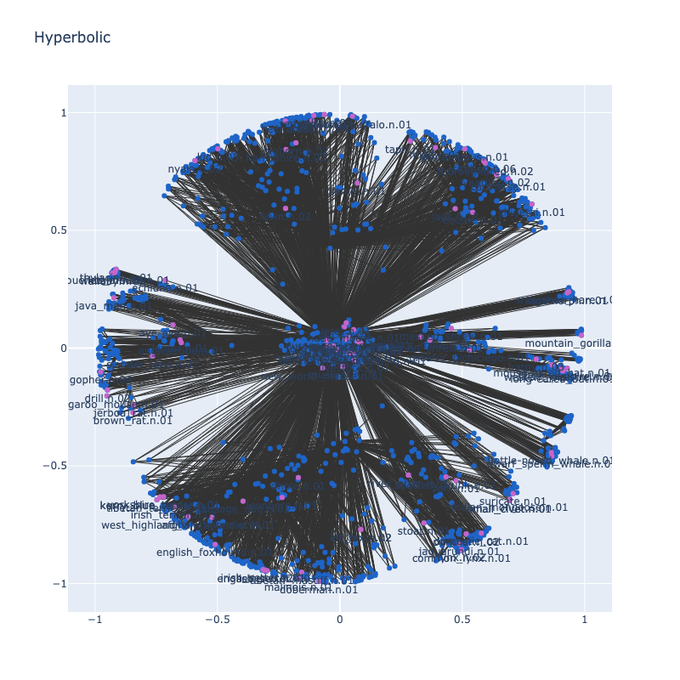





Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation. https://t.co/bxA1cW2i9e




Learning Point Embeddings from Shape Repositories for Few-Shot Segmentation. https://t.co/Cc0lUSsRME




Cross-Lingual Contextual Word Embeddings Mapping With Multi-Sense Words In Mind. https://t.co/7gWZPkIlFW
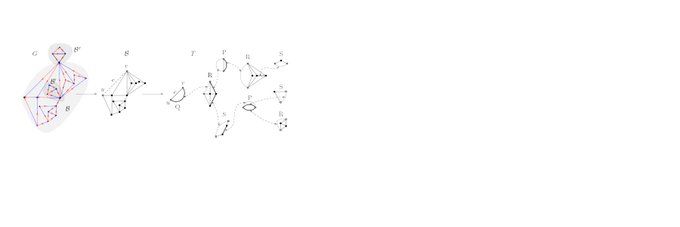





An Exploration on Coloring t-SNE Embeddings in Python https://t.co/H6QzANtbRm #DataScience #dataviz